
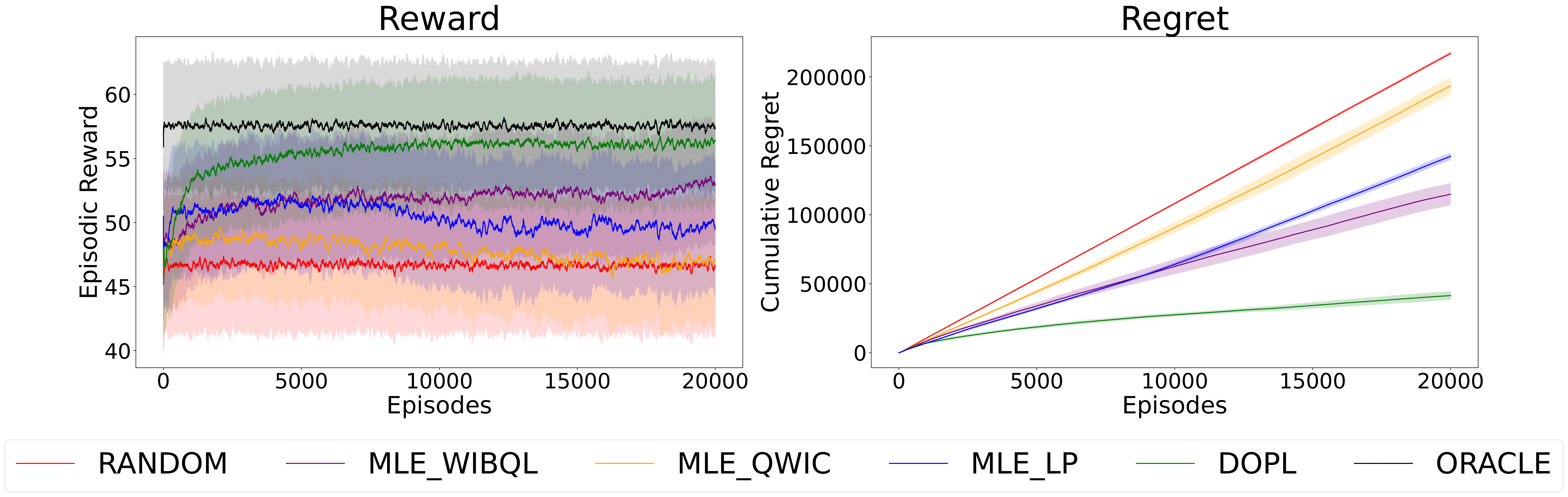
Addressing the limitations of conventional scalar rewards, DOPL leverages pairwise preference feedback to navigate restless multi-armed bandit problems. By directly employing online preference learning, the approach achieves sublinear regret of O(√(T ln T)), offering both theoretical guarantees and empirical validation for adaptive decision-making in environments where reward signals are scarce or imprecise.