
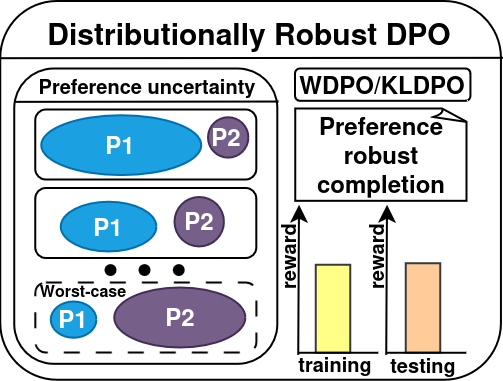
We propose two novel distributionally robust direct preference optimization (DPO) algorithms, Wasserstein DPO (WDPO) and Kullback-Leibler DPO (KLDPO), that mitigate large language model (LLM) alignment failures arising from shifting user preferences. We prove theoretical sample complexity guarantees for these algorithms and also demonstrate empirically that WDPO and KLDPO significantly improve alignment performance under preference distribution shifts.